Google Just Open-Sourced an AI Model That Beats Models 20x Its Size
Google DeepMind released Gemma 4 today, and this is one of those announcements that sounds like it only matters to AI engineers but has serious implications for every business thinking about AI strategy.
The short version: Google just released a family of four AI models under a fully open-source Apache 2.0 license. The largest model, with 31 billion parameters, ranks as the #3 open model in the world. The smallest runs on a smartphone with 4GB of RAM. And unlike most open-source releases that come with strings attached, this one has zero restrictions on commercial use.
If you're a business owner trying to figure out where AI fits into your operations, marketing, or customer experience, Gemma 4 just moved the goalpost. Here's what you need to know.
The Performance Story: Punching Way Above Their Weight
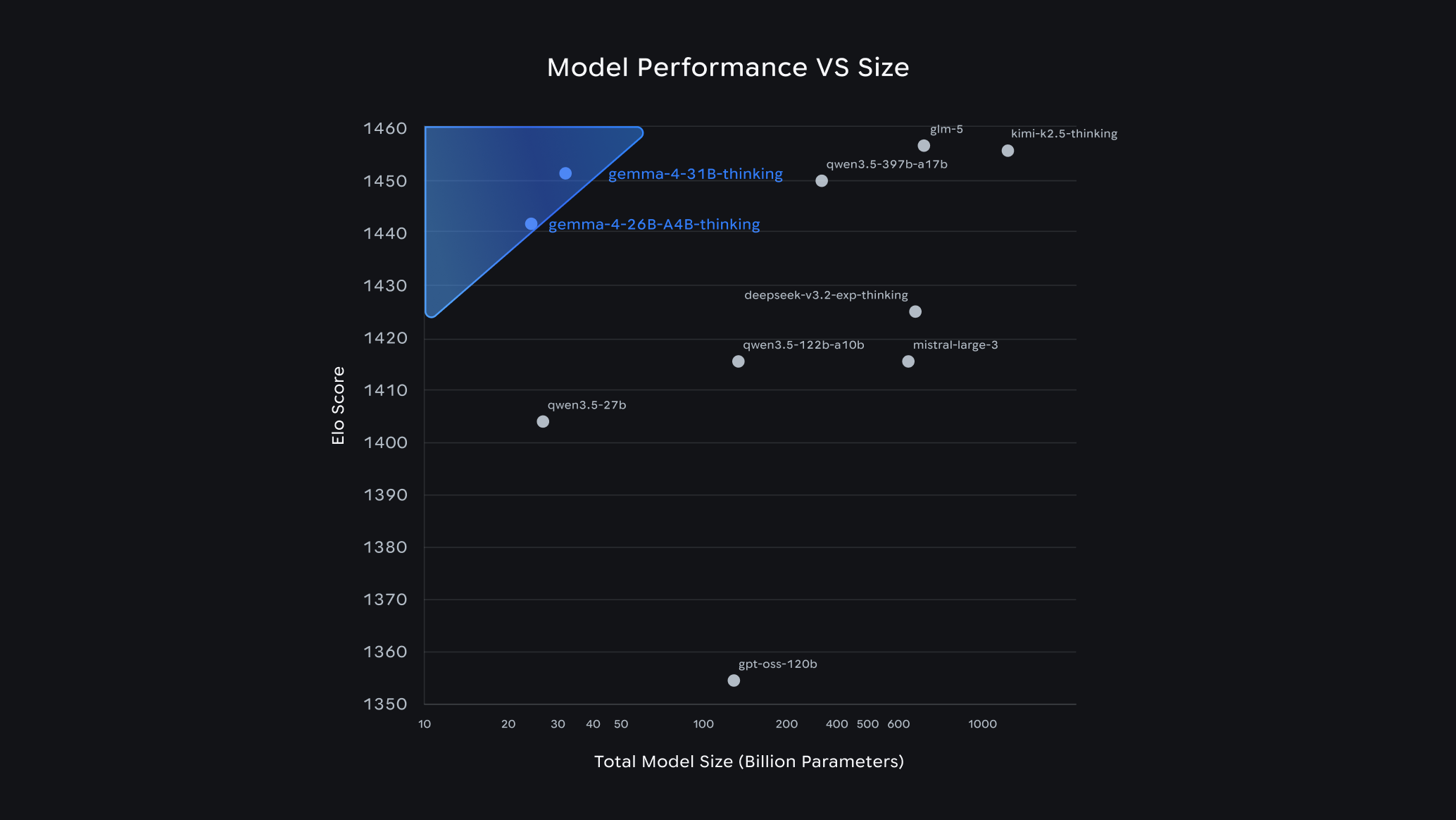
The headline number is the Arena AI leaderboard, which ranks AI models based on blind human evaluations. Gemma 4's 31B model scored 1452, placing it #3 among all open models in the world. The 26B model scored 1441, good for #6.
That alone would be impressive. What makes it remarkable is the size. The 26B model achieves that #6 ranking with only 3.8 billion active parameters at any given time. It uses a Mixture of Experts (MoE) architecture, meaning it routes each request to the most relevant subset of its 25.2 billion total parameters. The result is near-top-tier performance at a fraction of the computational cost.
To put that in perspective: Gemma 4's 26B model outperforms or matches models that are 10 to 20 times larger. That's not incremental improvement. That's a different category of efficiency.
The Benchmark Breakdown: The Numbers Are Hard to Ignore
The raw benchmarks tell a story of massive generational improvement. Compare Gemma 4's 31B model to the previous generation, Gemma 3 27B:
- AIME 2026 (advanced mathematics): Jumped from 20.8% to 89.2%. That's not a typo. A four-fold improvement in complex mathematical reasoning.
- LiveCodeBench v6 (real-world coding): 80% accuracy, making it a legitimate offline code assistant.
- Codeforces ELO (competitive programming): Went from 110 to 2150. For context, 2150 puts it in the top tier of competitive programmers globally.
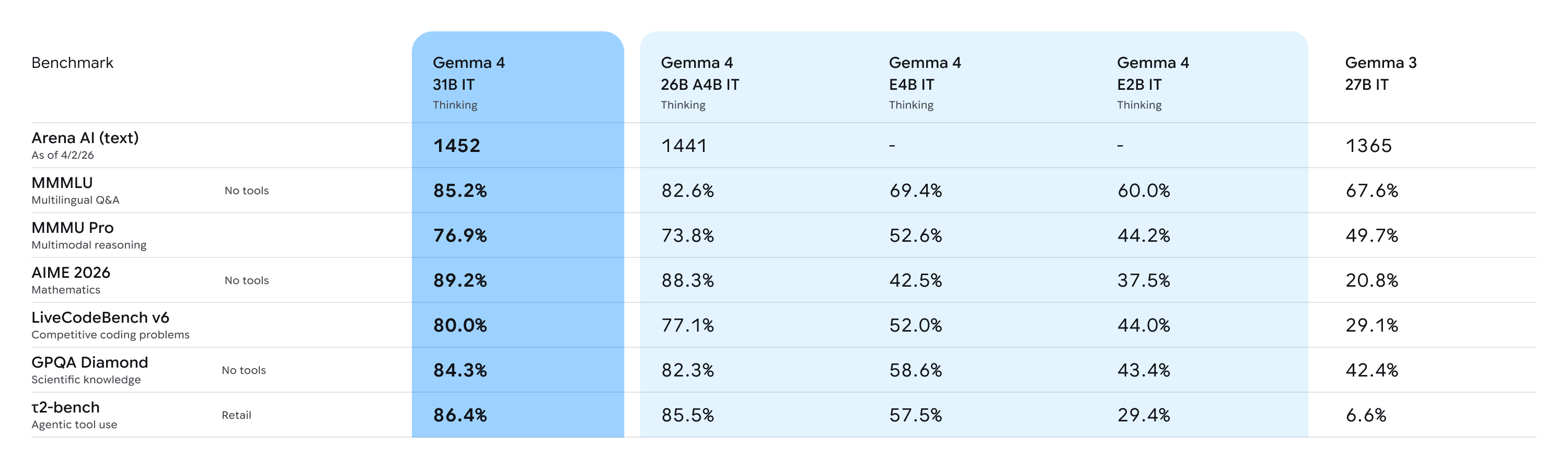
The 26B MoE model is nearly as strong, hitting 88.3% on AIME 2026 with only 3.8 billion active parameters. That level of reasoning capability at that efficiency level is something new in the open-source AI space.
These aren't theoretical benchmarks on artificial tasks. AIME tests the kind of multi-step logic that matters for real business applications: planning, analysis, problem-solving. Codeforces and LiveCodeBench test practical coding ability. The models are genuinely capable across reasoning, code generation, and language understanding.
What Makes Gemma 4 Different: The Capability Stack
Performance numbers are one thing. The feature set is what matters for actual deployment.
Advanced Reasoning
Gemma 4 models handle multi-step planning, deep logical reasoning, and complex problem decomposition. This isn't just answering questions. It's working through problems the way a human analyst would: identifying subproblems, sequencing steps, and synthesizing conclusions.
Agentic Workflows
All models support native function calling, structured JSON output, and system instructions out of the box. This is the infrastructure needed for AI agents that don't just generate text but actually take actions: looking up data, calling APIs, filling out forms, processing orders. The transition from "AI that writes" to "AI that does" requires exactly these capabilities.
Vision, Audio, and Multimodal Input
Every model in the family handles images and video. The two smaller models (E2B and E4B) add audio input and speech recognition. A single model that processes text, images, video, and audio opens up use cases that previously required stitching together multiple specialized systems.
Massive Context Windows
The smaller models handle 128,000 tokens of context. The larger models handle 256,000 tokens. That's enough to process entire codebases, full legal documents, or lengthy conversation histories without losing track of earlier information. For businesses, this means AI tools that maintain coherent understanding across complex, multi-part tasks.
140+ Languages
Global businesses and multilingual markets can deploy a single model that handles their entire language footprint. No separate models for each region. No quality dropoff in non-English languages.
The Apache 2.0 Shift: Why the License Matters More Than the Model
This is the part most people will overlook, and it might be the most significant piece of the announcement.
Previous Gemma releases came with Google's custom license that included usage restrictions. Gemma 4 ships under Apache 2.0, the same license used by projects like Kubernetes and Apache Kafka. No custom restrictions. No usage caps. No requirement to credit Google. Full commercial use, modification, and redistribution.
Clement Delangue, CEO of Hugging Face (the largest AI model repository), called it "a huge milestone." He's right. Here's why it matters for businesses:
- No vendor lock-in. You can fine-tune, modify, and deploy Gemma 4 models without any dependency on Google's cloud services or approval.
- Digital sovereignty. Companies and governments can run world-class AI entirely on their own infrastructure. No data leaves your building if you don't want it to.
- Enterprise compliance. Legal teams that have been blocking open-source AI adoption due to license ambiguity now have a clean, well-understood license to work with.
- Community innovation. Gemma models have already generated over 100,000 community variants across their lifecycle. Apache 2.0 removes the last friction point for developers and businesses building on top of these models.
Google's Gemma family has already been downloaded over 400 million times. With the license barrier removed, that number is going to accelerate.
What This Means for Your Business
AI Just Got Radically More Accessible
Here's the hardware reality of Gemma 4:
- E2B (2.3B effective parameters): Runs on a smartphone with 4GB of RAM
- E4B (4.5B effective parameters): Runs on a laptop with 8GB of RAM
- 26B MoE: Runs quantized on a 16GB GPU (a mid-range desktop graphics card)
- 31B Dense: Runs quantized on a 24GB GPU (a single high-end consumer GPU)
NVIDIA has day-one optimization support for RTX GPUs, DGX Spark workstations, and edge devices. The models work immediately with every major deployment framework: Hugging Face, Ollama, llama.cpp, vLLM, MLX, and more.
This changes the cost equation dramatically. You no longer need a $100K cloud AI budget to run serious AI capabilities. A capable AI model can now run on hardware that's already sitting in your office.
Local AI Is Now a Real Option
For businesses in regulated industries like healthcare, legal, and financial services, the ability to run AI entirely on local hardware is a game-changer. Patient data, case files, and financial records never leave your network. No API calls to external servers. No data processing agreements with cloud providers. Just capable AI running on your own machines.
The E4B model is particularly interesting here. A model that handles text, images, video, and audio on a standard laptop opens up field applications that were previously impractical: on-site inspections, client meetings, field service, and mobile sales tools that work without an internet connection.
Edge Deployment Changes the Game
Google announced Android AICore Developer Preview alongside Gemma 4, meaning these models can run natively on Android devices. Consider what that enables:
- Customer-facing apps with real AI capabilities that work offline
- Point-of-sale systems with intelligent product recommendations that don't depend on cloud connectivity
- Field service tools that analyze equipment photos and generate reports on the spot
- Real-time translation and transcription in face-to-face customer interactions
The AI doesn't live in the cloud anymore. It lives wherever your business operates.
Competitive Positioning
Here's the strategic question: if your competitors can now run top-tier AI on a laptop, what's your AI strategy?
The gap between "businesses using AI" and "businesses not using AI" is about to widen significantly. Not because the technology got more expensive or complex, but precisely because it got cheaper and simpler. When the barrier to entry drops this low, adoption accelerates. The businesses that move first build data advantages, workflow efficiencies, and customer experiences that become harder to replicate over time.
The Bottom Line
Gemma 4 represents something more significant than another model release. It's the moment where world-class AI became truly accessible to businesses of every size.
A model that ranks #3 globally among open models, supports vision, audio, and advanced reasoning, runs on a laptop, and ships under a fully open-source license with no commercial restrictions. Two years ago, that combination didn't exist at any price point. Today, it's free.
The practical implication is clear: the cost and complexity arguments against AI adoption are disappearing. What remains is the strategic question of where and how to deploy these capabilities in ways that drive real business value.
The companies that figure that out first will have a significant head start. The ones that wait will eventually adopt the same tools, but without the advantage of early learning, data accumulation, and operational refinement.
At 561 Media, we help South Florida businesses build digital strategies that put emerging technology to work. If you want to understand how AI fits into your marketing, operations, or customer experience, let's talk.